Competitive Programming Advent Calendar 2014の16日目の記事です。この記事では、プログラミングコンテストにおいてたまに出題されるものの、特に名前が付いてないしそこまで有名ではないかもしれないとあるテクニックを、個人的には割と面白いと感じたので紹介させていただきます。今までの中でも輪をかけて誰に得なのか分からない記事ですが、よろしければお付き合い下さい。
まず、2013年のICPCアジア地区予選会津大会のG問題として出題された以下の問題をご覧下さい
この問題をざっくりと説明すると、3次元空間上に点がたくさん存在するので、x座標もy座標もz座標もstrictlyに昇順となるような出来るだけ長い列を求めてくださいというものです。点の数は30万個以下です。
とりあえず、この手の問題の良くあるやり方として、まずz座標で昇順にソートして問題をx,yの2次元に落とします。すると、その状態でのx,y共に狭義単調増加となる最長部分増加列 (Longest Increase Sequence, LIS)を求めればいいことになります。LISは二分探索を使うことでO(nlogn)で解く手法が存在します。なので、元の問題が2次元の場合は一つの座標でソートすることでLISを求める問題に帰着することが出来ますが、3次元の場合はx座標もy座標も増加する部分列を求めなければいけません。LISにおいては、
という二つの処理が必要です。今回は値が2次元な場合で、そしてサイズを考えるとO(logn)くらいでこれらの処理を行わなければいけません。そこで、以下に説明するテクニックを用います。
まず、2次元で考える場合は、ある長さのLISの末尾要素は一意に定まりません。何故なら(1,6)と(5,2)のような2つの値はどちらが大きいか決められないためです(順序関係が定まらない)。ただ、x_i<=x_j,y_i<=y_jとなるような要素i,jは同時には存在し得ない(明らかにjの方はいらない)ので、ある長さのLISの末尾要素は下の図のようにxに関してはstrictlyに降順でyに関してはstrictlyに昇順となる要素の集合となります。
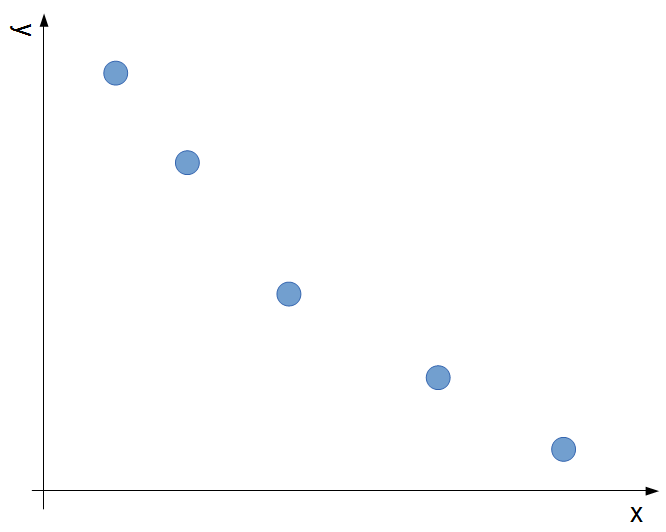
これを、(y,x)といったpair<int,int>型を作ってsetで管理しておくと、setの中でyの昇順かつxの降順に並ぶようになり処理が楽です(C++を想定しているので他の言語の場合は適宜脳内変換をお願いします)。
今見ている要素よりx,yともに小さい要素が一つでも存在するかどうかを判定する必要があります。下の図では今見ている要素が赤い点だとすると、その左下の領域に要素が一つでも存在するかどうかを判定するということです。
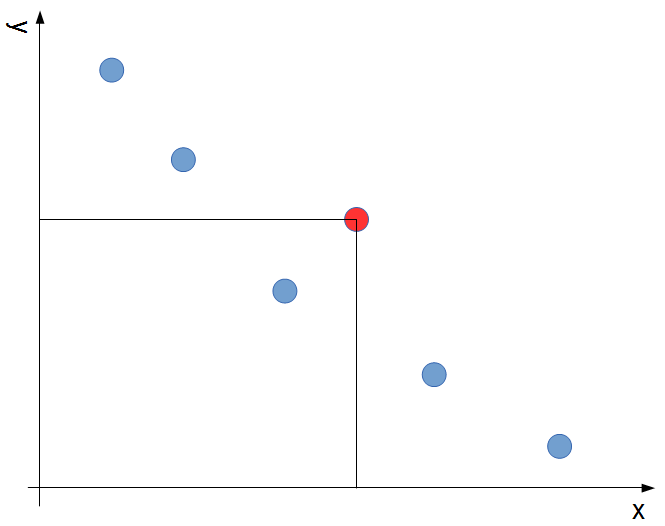
この場合は、「今見ている要素よりもyが小さい要素の中で最もyが大きい要素(下の図の黄色の点)」のxが今見ている要素のxより小さいかどうかを見ればいいです。もしその要素のxが今見ている要素のx以上だったら、それよりyの小さい要素はxは大きくなるので、「今見ている要素よりx,yともに小さい要素」は一つも存在しないことが分かるためです。
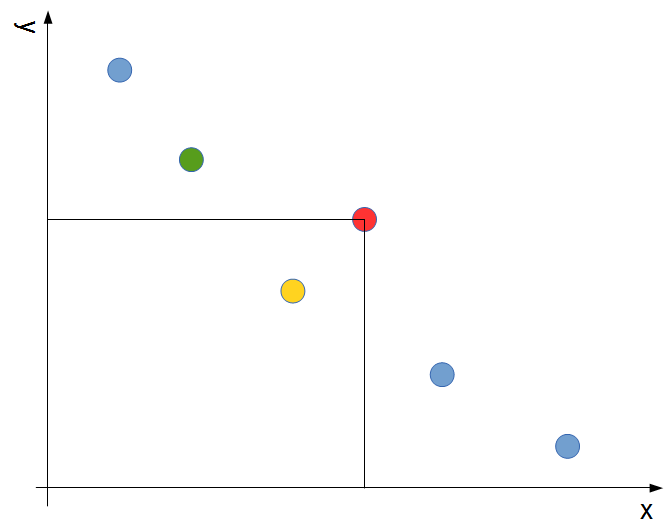
この、「今見ている要素よりもyが小さい要素の中で最もyが大きい要素」は、setで今見ている要素をキーにlower_boundをかけて見つかった要素(下の図の緑の点)の一つ前の要素となります。
もし、そのような要素のyが今見ている要素のyと同じであったら、さらに一つ前の要素が「今見ている要素よりもyが小さい要素の中で最もyが大きい要素」となります(下の図の黄緑の点)。
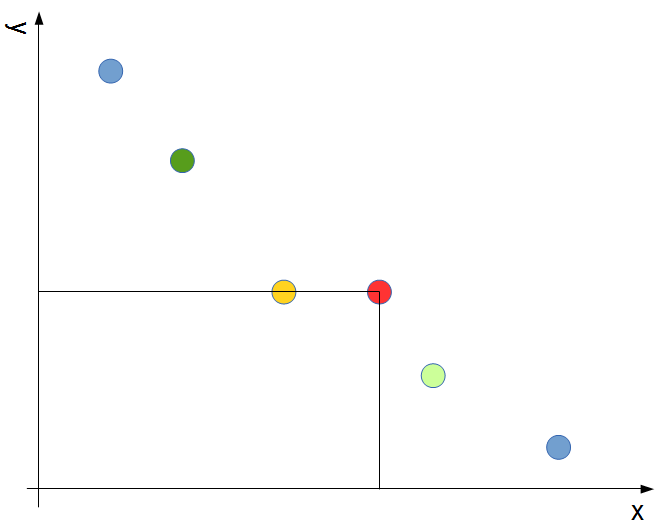
この処理の1回辺りの計算量はO(logn)となります。
以下のように、ある長さのLISの末尾要素の集合に新たな要素を加える場合、上で述べた処理を行うために「yの昇順かつxの降順に並んでいる」という条件を満たしている必要があります。よって、以下の図の赤い点を新たな要素として加える場合、その右上の部分の要素は全て消去しなければいけません。
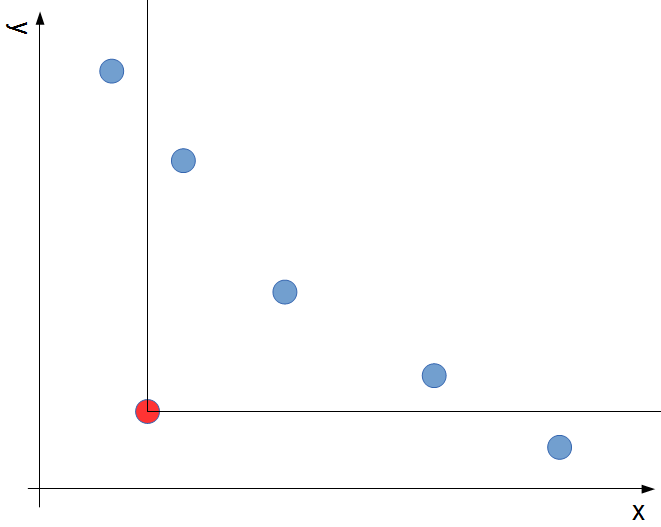
これを行うためには、新たな要素をキーにlower_boundをかけて見つかった要素(下の図の緑の点)から一つずつ先の要素を見て行きながらその要素を消していきます(下の図の黄色の点)。そして、xが新たな要素より小さくなったところで消去を止めます。
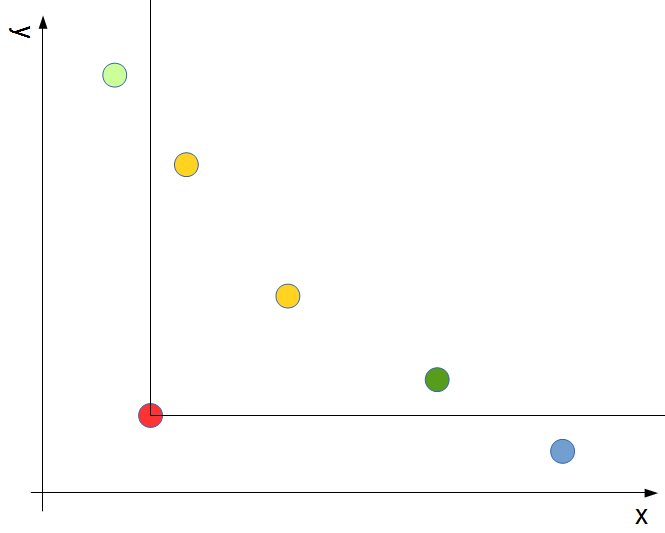
すると更新後の末尾要素の集合は下の図のようになり、少々見づらいですが「yの昇順かつxの降順に並んでいる」という条件を満たしているのでまた判定や更新の処理が行えるようになります。

要素の消去全体で合わせて高々n回しか行われないのでならし計算量はO(1)となるので、この処理1回辺りの計算量はO(logn)となります。
これにより、この問題が計算量O(nlog^2n)で解けるようになりました。
私がこの問題に通したソースコードを置いておきます
#define fi first #define se second typedef pair<int,int> pint; typedef pair<int,pint> tint; #define rAll(s) s.rbegin(),s.rend() #define REP(i,a,b) for(int i=a;i<b;i++) #define rep(i,n) REP(i,0,n) int A,B,C=~(1<<31),M=(1<<16)-1; int ran(){ A=36969*(A&M)+(A>>16); B=18000*(B&M)+(B>>16); return (C&((A<<16)+B))%1000000; } set<pint> s[364364]; vector<tint> v; //ここで末尾要素の集合を更新しています void ins(int a,pint p){ set<pint>::iterator it=s[a].lower_bound(p),it2=it;it2--; if(it2->se<=p.se) return; while(it->se>=p.se) s[a].erase(it++); s[a].insert(p); } //ここで末尾要素の集合に今見ている要素より小さい要素が存在するかをを判定しています bool ok(int a,pint p){ set<pint>::iterator it=s[a].lower_bound(p); while(it->se<p.se){ if(it->fi<p.fi) return true;it--; } return false; } int main() { int n,m,x,y,z,inf=1145141919; while(cin>>m>>n>>A>>B,m+n){ rep(i,3+n+m) s[i].clear(); s[0].insert(mp(-1,-1)); REP(i,1,3+n+m){ s[i].insert(mp(inf,-1));s[i].insert(mp(-1,inf)); } v.clear(); rep(i,m){ cin>>x>>y>>z;v.pb(mp(-z,mp(y,x))); } rep(i,n){ x=ran();y=ran();z=ran();v.pb(mp(-z,mp(y,x))); } sort(rAll(v)); int out=0; rep(i,n+m){ int lo=0,hi=out; while(hi>lo){ int mi=(hi+lo+1)/2; if(ok(mi,v[i].se)) lo=mi;else hi=mi-1; } out=max(out,lo+1);ins(lo+1,v[i].se); } cout<<out<<endl; } }
ここで、今回の記事で紹介したテクニックとは関係無いですがもう一つちょっとした実装上のテクニックを紹介すると、
v.pb(mp(-z,mp(y,x)));
といった形で要素の配列を作ることで、zに関しては昇順であるがy,xに関しては降順にソートしているという点です。もし全てに関して昇順にソートすると、例えば(z,y,x)=(8,1,0)となる要素の後に(8,9,3)となる要素が来ますが、この2つの要素はzが等しいので両方ともLISに含めることは出来ないにもかかわらず、(y,x)=(1,0)となる要素が長さ1のLISの末尾要素に入ってしまっていると2つ目の要素が長さ2のLISの末尾要素になると判定されてしまうため、答えが変わってしまいます。
これを避けるためには判定と更新を別のタイミングで行う(zが切り替わるタイミングで更新を行う)必要がありますが、「zに関しては昇順であるがy,xに関しては降順」にソートすると、(8,9,3)という要素を見る時は、(8,1,0)などといった「zは同じだがx,yは共に小さい」要素はまだ見ていないので、特に判定と更新を別のタイミングで行わなくても正しい答えが出るようになります。
なお、この「ソートの基準を少し変える」テクニックは、会津大会の本番中にこのG問題を担当していたチームメイトが使っていたものです。私は当時はこのテクニックを知らず、デバッグの際に印刷されたコードを見て「この部分が間違ってるんじゃないの?」といって説明させて無駄な時間を消費してしまいました・・・
このようなテクニックを用いる問題として、他には以下のような問題が存在します
特に前者のFishはJOI勢にとって有名らしいので、この記事で紹介したテクニックはJOI勢には「Fishで使うやつ」といった感じで広まっているようです(「StarrySky木」ほどメジャーではないみたいですが)。
また、このテクニックが想定解ではない問題に関しても、このテクニックを知ってると無理やり通すことができることがあります。CatchTheBeat(SRM623DIV1Medium)は、しっかり考察を行えば計算量をO(nlogn)にできるみたいですが、サイズが微妙だったためこのテクニックを用いてO(nlog^2n)でも通すことが出来ました(setのlower_boundなのでlognといってもSegmentTreeよりは春香に速いはずです)。
ここに書いた以外でもこのテクニック(名前が付いてないので最後まで微妙な言い回しですみません)を使えば解ける問題があるかもしれませんし、このテクニックを知ることでまた違った景色が見えてくるかもしれません。
今年1年も様々なコンテストが開催されて数多くの問題に出会うことが出来ました。来年もまた素晴らしい問題たちに出会えることを祈りつつ、良いお年を!