Competitive Programming Advent Calendar 2014の16日目の記事です。この記事では、プログラミングコンテストにおいてたまに出題されるものの、特に名前が付いてないしそこまで有名ではないかもしれないとあるテクニックを、個人的には割と面白いと感じたので紹介させていただきます。今までの中でも輪をかけて誰に得なのか分からない記事ですが、よろしければお付き合い下さい。
まず、2013年のICPCアジア地区予選会津大会のG問題として出題された以下の問題をご覧下さい
この問題をざっくりと説明すると、3次元空間上に点がたくさん存在するので、x座標もy座標もz座標もstrictlyに昇順となるような出来るだけ長い列を求めてくださいというものです。点の数は30万個以下です。
とりあえず、この手の問題の良くあるやり方として、まずz座標で昇順にソートして問題をx,yの2次元に落とします。すると、その状態でのx,y共に狭義単調増加となる最長部分増加列 (Longest Increase Sequence, LIS)を求めればいいことになります。LISは二分探索を使うことでO(nlogn)で解く手法が存在します。なので、元の問題が2次元の場合は一つの座標でソートすることでLISを求める問題に帰着することが出来ますが、3次元の場合はx座標もy座標も増加する部分列を求めなければいけません。LISにおいては、
という二つの処理が必要です。今回は値が2次元な場合で、そしてサイズを考えるとO(logn)くらいでこれらの処理を行わなければいけません。そこで、以下に説明するテクニックを用います。
まず、2次元で考える場合は、ある長さのLISの末尾要素は一意に定まりません。何故なら(1,6)と(5,2)のような2つの値はどちらが大きいか決められないためです(順序関係が定まらない)。ただ、x_i<=x_j,y_i<=y_jとなるような要素i,jは同時には存在し得ない(明らかにjの方はいらない)ので、ある長さのLISの末尾要素は下の図のようにxに関してはstrictlyに降順でyに関してはstrictlyに昇順となる要素の集合となります。
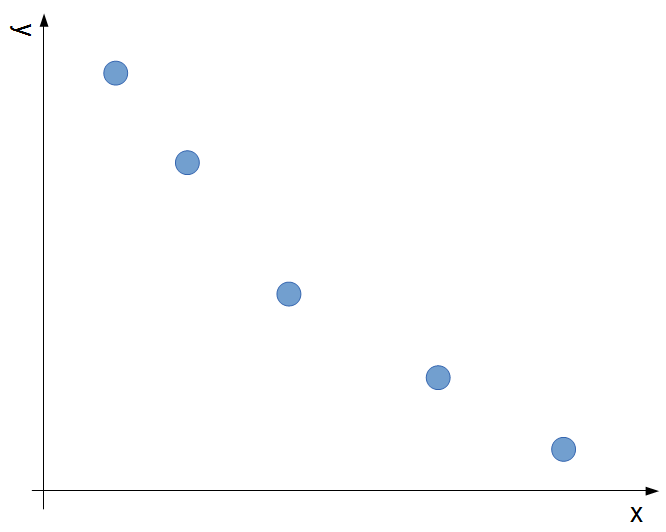
これを、(y,x)といったpair<int,int>型を作ってsetで管理しておくと、setの中でyの昇順かつxの降順に並ぶようになり処理が楽です(C++を想定しているので他の言語の場合は適宜脳内変換をお願いします)。
今見ている要素よりx,yともに小さい要素が一つでも存在するかどうかを判定する必要があります。下の図では今見ている要素が赤い点だとすると、その左下の領域に要素が一つでも存在するかどうかを判定するということです。
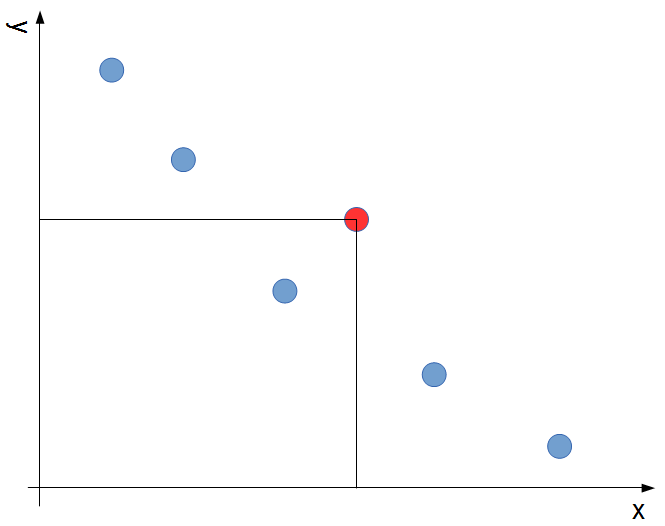
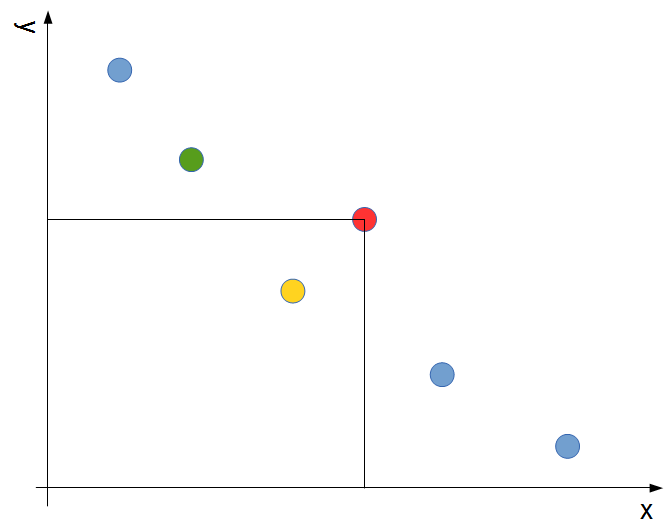
この場合は、「今見ている要素よりもyが小さい要素の中で最もyが大きい要素(下の図の黄色の点)」のxが今見ている要素のxより小さいかどうかを見ればいいです。もしその要素のxが今見ている要素のx以上だったら、それよりyの小さい要素はxは大きくなるので、「今見ている要素よりx,yともに小さい要素」は一つも存在しないことが分かるためです。
この、「今見ている要素よりもyが小さい要素の中で最もyが大きい要素」は、setで今見ている要素をキーにlower_boundをかけて見つかった要素(下の図の緑の点)の一つ前の要素となります。
もし、そのような要素のyが今見ている要素のyと同じであったら、さらに一つ前の要素が「今見ている要素よりもyが小さい要素の中で最もyが大きい要素」となります(下の図の黄緑の点)。
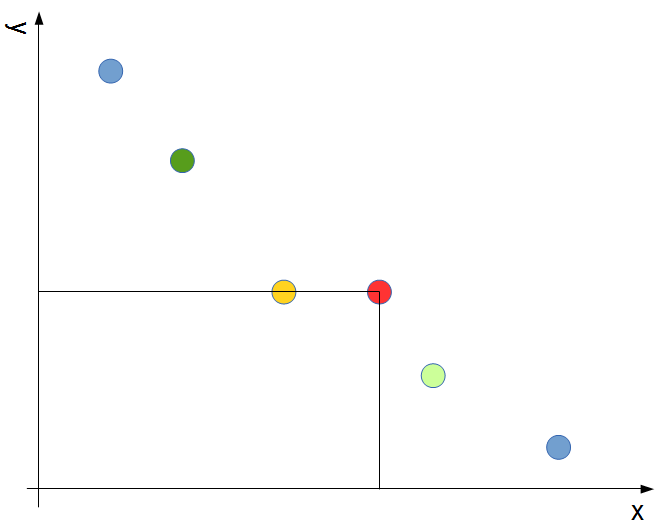
この処理の1回辺りの計算量はO(logn)となります。
以下のように、ある長さのLISの末尾要素の集合に新たな要素を加える場合、上で述べた処理を行うために「yの昇順かつxの降順に並んでいる」という条件を満たしている必要があります。よって、以下の図の赤い点を新たな要素として加える場合、その右上の部分の要素は全て消去しなければいけません。
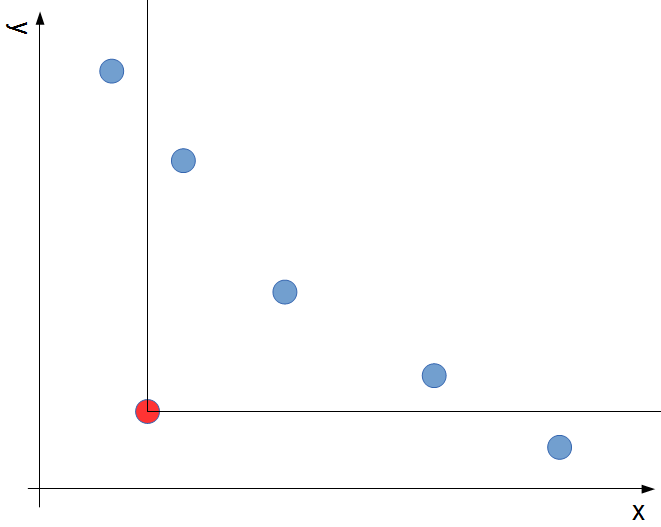
これを行うためには、新たな要素をキーにlower_boundをかけて見つかった要素(下の図の緑の点)から一つずつ先の要素を見て行きながらその要素を消していきます(下の図の黄色の点)。そして、xが新たな要素より小さくなったところで消去を止めます。
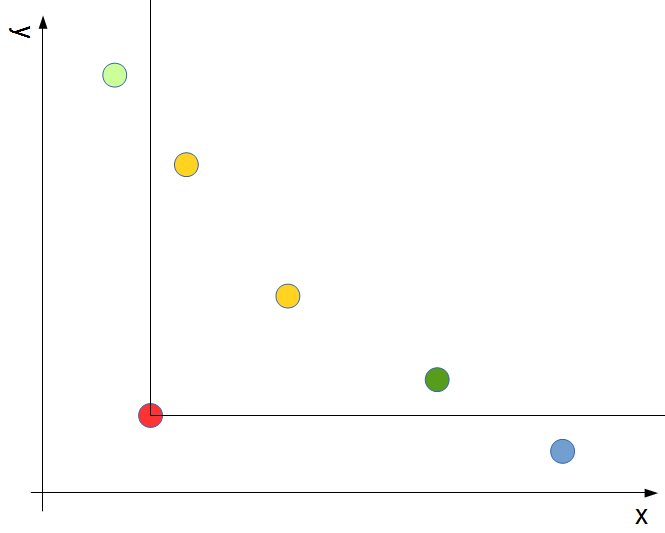
すると更新後の末尾要素の集合は下の図のようになり、少々見づらいですが「yの昇順かつxの降順に並んでいる」という条件を満たしているのでまた判定や更新の処理が行えるようになります。

要素の消去全体で合わせて高々n回しか行われないのでならし計算量はO(1)となるので、この処理1回辺りの計算量はO(logn)となります。
これにより、この問題が計算量O(nlog^2n)で解けるようになりました。
私がこの問題に通したソースコードを置いておきます
#define fi first #define se second typedef pair<int,int> pint; typedef pair<int,pint> tint; #define rAll(s) s.rbegin(),s.rend() #define REP(i,a,b) for(int i=a;i<b;i++) #define rep(i,n) REP(i,0,n) int A,B,C=~(1<<31),M=(1<<16)-1; int ran(){ A=36969*(A&M)+(A>>16); B=18000*(B&M)+(B>>16); return (C&((A<<16)+B))%1000000; } set<pint> s[364364]; vector<tint> v; //ここで末尾要素の集合を更新しています void ins(int a,pint p){ set<pint>::iterator it=s[a].lower_bound(p),it2=it;it2--; if(it2->se<=p.se) return; while(it->se>=p.se) s[a].erase(it++); s[a].insert(p); } //ここで末尾要素の集合に今見ている要素より小さい要素が存在するかをを判定しています bool ok(int a,pint p){ set<pint>::iterator it=s[a].lower_bound(p); while(it->se<p.se){ if(it->fi<p.fi) return true;it--; } return false; } int main() { int n,m,x,y,z,inf=1145141919; while(cin>>m>>n>>A>>B,m+n){ rep(i,3+n+m) s[i].clear(); s[0].insert(mp(-1,-1)); REP(i,1,3+n+m){ s[i].insert(mp(inf,-1));s[i].insert(mp(-1,inf)); } v.clear(); rep(i,m){ cin>>x>>y>>z;v.pb(mp(-z,mp(y,x))); } rep(i,n){ x=ran();y=ran();z=ran();v.pb(mp(-z,mp(y,x))); } sort(rAll(v)); int out=0; rep(i,n+m){ int lo=0,hi=out; while(hi>lo){ int mi=(hi+lo+1)/2; if(ok(mi,v[i].se)) lo=mi;else hi=mi-1; } out=max(out,lo+1);ins(lo+1,v[i].se); } cout<<out<<endl; } }
ここで、今回の記事で紹介したテクニックとは関係無いですがもう一つちょっとした実装上のテクニックを紹介すると、
v.pb(mp(-z,mp(y,x)));
といった形で要素の配列を作ることで、zに関しては昇順であるがy,xに関しては降順にソートしているという点です。もし全てに関して昇順にソートすると、例えば(z,y,x)=(8,1,0)となる要素の後に(8,9,3)となる要素が来ますが、この2つの要素はzが等しいので両方ともLISに含めることは出来ないにもかかわらず、(y,x)=(1,0)となる要素が長さ1のLISの末尾要素に入ってしまっていると2つ目の要素が長さ2のLISの末尾要素になると判定されてしまうため、答えが変わってしまいます。
これを避けるためには判定と更新を別のタイミングで行う(zが切り替わるタイミングで更新を行う)必要がありますが、「zに関しては昇順であるがy,xに関しては降順」にソートすると、(8,9,3)という要素を見る時は、(8,1,0)などといった「zは同じだがx,yは共に小さい」要素はまだ見ていないので、特に判定と更新を別のタイミングで行わなくても正しい答えが出るようになります。
なお、この「ソートの基準を少し変える」テクニックは、会津大会の本番中にこのG問題を担当していたチームメイトが使っていたものです。私は当時はこのテクニックを知らず、デバッグの際に印刷されたコードを見て「この部分が間違ってるんじゃないの?」といって説明させて無駄な時間を消費してしまいました・・・
このようなテクニックを用いる問題として、他には以下のような問題が存在します
特に前者のFishはJOI勢にとって有名らしいので、この記事で紹介したテクニックはJOI勢には「Fishで使うやつ」といった感じで広まっているようです(「StarrySky木」ほどメジャーではないみたいですが)。
また、このテクニックが想定解ではない問題に関しても、このテクニックを知ってると無理やり通すことができることがあります。CatchTheBeat(SRM623DIV1Medium)は、しっかり考察を行えば計算量をO(nlogn)にできるみたいですが、サイズが微妙だったためこのテクニックを用いてO(nlog^2n)でも通すことが出来ました(setのlower_boundなのでlognといってもSegmentTreeよりは春香に速いはずです)。
ここに書いた以外でもこのテクニック(名前が付いてないので最後まで微妙な言い回しですみません)を使えば解ける問題があるかもしれませんし、このテクニックを知ることでまた違った景色が見えてくるかもしれません。
今年1年も様々なコンテストが開催されて数多くの問題に出会うことが出来ました。来年もまた素晴らしい問題たちに出会えることを祈りつつ、良いお年を!
最適戦略は「敵の最も大きいのを潰す」か「自分の大きい方2つを合併する」のどちらか。
ただし、敵の最も大きいのを潰せた時は、敵は自分の最も大きいのを潰せないので、最初の2手だけ調べればいい。(練習会では潰して潰して…とずっと繰り返せると思ってた。頭弱い)
#define REP(i,a,b) for(int i=a;i<b;i++) #define rep(i,n) REP(i,0,n) lint a[100010],b[100010],c[100010]; bool cal(){ lint x=a[0],y=b[0]; rep(i,100005){ x+=a[i+1];if(y>x) return false; y+=b[i+1];if(x>y) return true; } } int main() { int n,m; for(int i=1;cin>>n>>m;i++){ memset(a,0,sizeof(a));memset(b,0,sizeof(b));memset(c,0,sizeof(c)); rep(i,n) cin>>a[i];rep(i,m) cin>>b[i]; sort(a,a+n);reverse(a,a+n);sort(b,b+m);reverse(b,b+m); cout<<"Case "<<i<<": "; if(cal()){ cout<<"Takeover Incorporated"<<endl; } else{ if(a[0]<b[0]) cout<<"Buyout Limited"<<endl; else{ rep(i,m-1) c[i]=b[i+1]; memcpy(b,a,sizeof(a));memcpy(a,c,sizeof(c)); if(cal()) cout<<"Buyout Limited"<<endl; else cout<<"Takeover Incorporated"<<endl; } } } }
Competitive Programming Advent Calendar Div2013の21日目の記事です。この記事では自分が今まで解いた問題の中で解法に衝撃を受けたものを2つほど紹介したいと思います。去年と一昨年の記事は一応初級者の方の上達に役に立つかもしれないものだったのに対し今年のは本当に誰にとって得なのか良く分からない個人的な趣味だけで書いた記事ですがよろしければお付き合い下さい。
問題概要
赤青黄緑の4色のボールをシリンダーに入れていく。上のL個のボールの色が同じだとそのL個のボール全てが消える。ボールを順番にN個入れた後シリンダーが空になるようなボールの入れ方は何通りあるか。
要するに一列のぷよぷよです。題意が良く伝わらなかった場合はすみませんが上のリンクから原文を見て下さい。さて、本番でこの問題を見た時は「A個目からB個目までのボールで全部消える並び方」を区間DPで求めることを考えてたのですが、O(N^3)なので計算量が危ないですし、そもそも重複なく数え上げるのが大変で解けずじまいでした。
ですが、SRM終了後のLayCurseさんの放送を見て衝撃を受けました。解法はやはりDPだったのですが、その更新式はたったこれだけだったのです。
if(j==0) dp[i+1][L-1]+=dp[i][j]*4;
else{
}
どういうことかというと、「i個目まで入れた」というのに加えて、「あと最低j個のボールを入れれば全部消える」という情報をキーに持ってDPを行うのです。そうすると、次に4色のボールのうち正しい色のボールを入れれば「全部消えるために入れる必要のある最小のボールの数」は1つ減り、それ以外の3色のボールを入れれば、まずそのボールと同じ色のボールをL個つなげて消さなくてはいけないので、「全部消えるために入れる必要のある最小のボールの数」はL-1個増えるのです。
ただし、「全部消えるために入れる必要のある最小のボールの数」が0個、つまりi個目までボールを入れた状態で既に全部のボールが消えている場合には、どの色のボールを入れても「全部消えるために入れる必要のある最小のボールの数」はL-1個増えるので、そこだけは例外扱いする必要があります。
それにしても、本番中1時間くらい考えても全然分からなかった問題が、こんなにシンプルに解けてしまうことに衝撃を受けました。
続いては最小カットです。最小カットは最大フローと等しいので、問題を最小カットに帰着できれば最大流ライブラリを用いて解くことができるという形で、競技プログラミングではしばしば用いられる定理です。最近のSRMのMedium問題にこの題材が出されたり、また診断人さんの生放送で最小カット講座が行われたりしているので、ご存知の方も多いかもしれません。
自分もこの定理は(競技プログラミングにおいては)「最小カットを求めるためのもの」と思っていましたが、次の問題を見てその考えを改めることになります。
問題概要
平行な壁に囲まれた通路に、いくつかの断面が凸多角形となる高さ無限の柱があります。風が通路の入り口から出口に向かって吹いているとき、1秒ごとに通路で流されることができる空気の最大量を求めなさい。ただし、幅wの通り道に対して風は1秒ごとに最大でwの空気量だけ通ることができる。
相変わらず概要が分かり辛くてすみません…。要するに「通路の入り口から出口までの最大フローを求める」という問題なのですが、多角形同士の位置関係をグラフに落とし込むのが極めて難しいです。恐らく、空間を適切に分割して、それぞれの分割された空間が点、分割された空間同士の間にある線分が辺(そしてその線分の長さが辺の容量)というグラフを作ることが出来れば解けるのでしょうが…。
解放の糸口すらつかめず諦めて解答(正解者のコード)を見てしまったのですが、これが予想より遥かにシンプルでびっくり。両側の壁と各柱を点として、2点間の辺の長さは相当する物体同士の最短距離、というグラフを作り、片方の壁からもう片方の壁までの最短距離を求める、といったものでした。
最初に解答を見たときは何故これで正しい答えが出るのかすぐには分かりませんでしたが、つまり
最小カットを求めることで、最大フローを求める
という解法だったのです。
片側の壁からもう片側の壁までの経路に壁を作れば風は全く通ることができません。つまりこの経路の長さがカットの大きさになっているので、最小カット=最短経路を求めれば最大フローが求まるという訳です。この最大フロー最小カット定理を逆パターンで使う問題は初めてみたので中々に衝撃的でした。
短い上に本当に誰が得するのか分からない記事になってしまってすみません(汗)。ただ、このように解法を知った時のインパクトが大きいと、解法が頭に残りやすく次に似たような問題に当たった時に参考にしやすいのでいいですね。自分もこの記事を書くときに他にも衝撃的な解法だった問題が無かったか思い出そうとしたものの思い出せず…。この程度しか記憶に残ってないので最近コンテストで中々思うように行かないのかもしれませんね(汗)。
今年も残り10日ほどとなりました。一応まだSRMやCodeforcesなどがいくつか残ってはいますが、みなさん今年1年間お疲れ様でした。また来年も競技プログラミングを頑張りましょう。よいお年を!
CompetitiveProgramming Advent Calendar Div2012の13日目の記事です。今回は、競技プログラミング(特にTopcoder)の練習法について書こうと思います。正直自分もまだまだ競技プログラミングに関して修行が足りていない身ではありますが、一応ある程度の経験はある訳ですし、ことTopcoderにおいてはRedCoderという実績があるので、少しはみなさんの上達の助けになるのではないかと思いましたので。あと、「上達するには練習問題をとけばいいって言うけど、どう解けばいいのか分からない」という意見も見かけたのもこういう記事を書こうと思ったきっかけです。
まず普通に問題を開いて、自分で解法を考えてコーディングしてデバッグしてをやってみましょう。それで正解できればもちろん問題無いですが、どうしても解法が思いつかない場合、又は解法は浮かんだのにどうしても答えがあわないといった時は、答えを見てしまいましょう。答えというのはその問題に対して正解したコードのことです。答えを見てしまうというのはギブアップして安直な道に進んでるみたいで抵抗があるという方もいると思いますが、いくら考えても出てこないものは出てこないで、ストレスを溜めてしまう前に答えを見てしまいましょう。(むしろ自力でスラスラ解けるような問題だったら解いてもあまり練習にはなりません。確かに解くスピードは上がりますけど…)
で、答えのコードを見て解法を理解したら、実際に自分でその解法を実装して通してみましょう。ただ他人の答えを写すだけなんて…と思う人もいるかもしれませんが、この「実際に自分で実装して通す」という過程で身に付くものも多いので。コードを見てどのような処理が行われているかを把握して、自分で考えてコードを書くというのが理想ですが、行われている処理が良く分からない場合はコードを丸写ししてみるのもいいと思います。丸写ししているうちに「そうか、ここではこういう処理を行っているのか」と気付くこともあります。
で、この「実際に正解したコードを見る」という過程が重要なために、練習に使用する問題としてはTopcoderのSingleRoundMatchで出題された問題を使うことをお勧めします。ArenaのPracticeRoomで練習すれば手元の環境は必要ありませんしね。PracticeRoomではwriter解を始めPracticeRoomに提出された他のコードを見ることも出来ますし、TopcoderのサイトではそのSRMの本番中に通ったコードを見ることも出来ます(https://www.otinn.com/のstatistics->sumarriesというところで全てのSRMの結果が見れて、問題ごとの点数の部分をクリックするとその人のコードが見れるのでお勧めです)。コードを読んだだけでは理解できない点はMatchEditorials(TopcoderのページのCompetitions->Algorithm->SRM->Statisticsから)を読めばいいと思います。ついでに言えば、自力で解けた問題に関しても、余裕があれば他の人のコードやEditorialsを読むことによってよりシンプルな解法に気付いたりできると思います。またSRMはDivisionが2つあり、それぞれ難易度順に並んだ3問があるので、問題を解く前から難易度を予想でき、自分にあった難易度の問題を選べると言う利点もあります。
もちろんこれは練習問題に限らず、実際にSRMに出た後も同様です。解けそうだけど解けなかった問題はどこが間違ってたのかを確認してPracticeRoomで通して置くことをおすすめします。やはりコンテストに出たら出っぱなしではなくこの様に復習すると実力は伸びやすいと思います(自分も最初は出っぱなしで灰色でしたが、復習するようになってからちょっとずつレートが上がるようになりました)。
あと余談といえば余談ですが、問題は新しい方から解きましょう。現在Arena上にある最古のセットであるSRM144のDiv2の問題はDiv2にしてはやたら面倒で、「とりあえず最初からやろう」とSRM144から解き始めて心を折られてしまう人もいました。これに比べたら新しい問題の方が簡単ですし、「あ、この問題は本番で解いたし解法も覚えてる」と周りの方に助言してもらえる確率も上がります。
ちなみに、他にもAtcoderやAOJでも正解したコードを見ることが出来ます。こちらはTopcoderと違って日本語なのでその点でのとっつき易さもあると思います。
問題を解いてて分からないことがあったら周りの経験者の方にどんどん質問していきましょう。自分も昔はよくchokudaiさんにメッセで質問して答えて頂いてたのが上達の大きな要因になっていると思います。
周りにそういう質問が出来る人がいないという場合でも、Twitterで競技プログラマーの人たちをフォローしてたりすると、SRMの終了直後はみんな問題の話をしてるので、それを参考にしたり、あとは解法に関して質問しても答えてくれると思います。もちろん事情があってTwitterを使いたくないという方もいるでしょうが、そのような場合でも、Twitterの競技プログラマーのリスト(探せば見つかると思います)をブックマークするなどしておけば、SRM直後に問題に関する色々な知見が得られると思います。
直接競技プログラミングの実力の向上には関係ないように思えますが、オンサイトイベントに参加することはお勧めします。例えば、今月の頭にあったUTPC2012とかはコンテストの後に懇親会をやってましたし、最近はDeNAさん主催のTopcoderOnsiteInJapanなんかも行われています。
こういうオンサイトイベントに参加してみて、今までハンドルネームしか知らなかった方々と実際に会ってみると、本当に面白くて魅力がある方々だというのが分かると思います。実際に口頭で質問や議論をすることが出来ますし、何より競技プログラミングがもっと好きになれるんじゃないでしょうか。自分も競技プログラミングの問題を考えるのが好きだったっていうのももちろんありますが、それを通じて色々な人と知り合えたっていうのも今まで楽しく続けてこれた大きな理由だと思います。
なので、地理的な問題が無ければ是非積極的にこういったオンサイトイベントに参加してみるのをお勧めします。(もちろんこういうイベントに参加しづらいからといって競技プログラムをやる上で不都合というわけでもないです)
とりあえずこんな感じで、結局殆どTopcoderに関する話になってしまいましたが自分の考える上達法は伝えられたと思います。まぁTopcoderにおける実力が伸びればもちろん競技プログラミングの実力が伸びてるってことなので、他のコンテスト等でも充分に役立つと思います(傾向の違いもあるので一概には言えませんが)。あともちろんここに述べたのはあくまで方法の1つなので、他の方法を聞いてみたり試してみたりするのもいいと思います。ただ自分は(分かる問題も分からない問題も)「実際に正解になったコードを見る」ことが大事だと思っているのでこのような記事を書きました。
それではみなさん、楽しいTopcoderライフを!(2年連続で同じ締め)
![]() be_a_prgrmr2014/07/23 02:44とてもためになりました
be_a_prgrmr2014/07/23 02:44とてもためになりました
CompetitiveProgrammingAdventCalenderの19日目の記事です。この記事では自分の好きなアルゴリズムやそれを使うSRMの問題なんかについて書いていこうかと思います。講座的な記事というよりは単純に自分の思うままに好きな内容を書いた読み物的な記事になるかと思いますが、Topcoderをやってる人なら多分楽しめるんじゃないかと思うので最後までお付き合いください。(特に断りが無い限り問題は全てDiv1の問題です)
まずはアルゴリズムの王道ともいえるDPから。競技プログラミングでもやっぱりDP系の問題が一番多いんじゃないんでしょうか。特にTopcoderではDP率が高いんで正直DPさえできればRedcoderになれるんじゃないかっていう。
そしてここに書くぐらいなんで自分ももちろんDPが好きな訳です(結構ぽろぽろDPの問題落とすんで決して胸を張って得意とも言えないけど)。自分で何となく問題を考えてみると大体DPに帰着できる問題になっちゃいますしね。DPの基本的な考え方とかはchokudaiさんの最強最速アルゴリズマー養成講座にも記事があるんで「DPについてまだどうも良く分からない」という人はそちらを参考にするといいと思います(ここを読んでる人で読んでない人もいないと思いますが)。
後は最初にも書いたようにとにかく色々な問題があるのでとにかく解きまくって慣れるしかない部分もあるとは思います。他の人のコード読んだりしてるうちに最初はもやもやとしてたのが段々霧が晴れたように理解できるようになってくると思います。DPが分かるようになるとTopcoderライフが全く変わる…と思います。
さて、DPに関する好きなSRMの問題ですが、DPで巧妙な問題な問題はいくらでもあるので、あえて簡単でシンプルな問題を選びました。SRM412Easy,ForbiddenStringsです。DPの入門にはうってつけの問題だと思うので是非トライしてみて下さい。(chokudaiさんの講座でもこれを例題に挙げれば良かったと思うのですが…)
問題概要(ForbiddenStrings)
30以下の整数nが与えられる。A,B,Cからなる同じ文字が3文字続かない長さnの文字列の数を返せ。
続いては二分探索です。DPより頻度は少ないですがこれも使えるようになると大きいと思います。自分にとって印象深い二分探索の問題はSRM421Easy,EquilibriumPointsです。
問題概要(EquilibriumPoints)
1次元座標上に惑星がn(2<=n<=50)個あり、座標をx[i],重さをm[i]として与えられている。引力は惑星の重さに比例し惑星からの距離の2乗に反比例する。この時左右からの引力が釣り合う点を全て求めよ。
当時はDiv2Mediumとしてこの問題に挑んだのですが、多項式の解として求めようとしたりして本番中には解けずじまい。SRM直後にchokudaiさんに質問して二分探索で解けると言われた時は衝撃を受けました。ソートされた要素の探索としての二分探索は知ってましたが、こういう時にも適応できると知って世界が変わりました。SRM380Medium,CompilingDecksWithJokersなんかも二分探索を適用するとびっくりするぐらい簡単に解ける問題例ですね。
あと二分探索は、DP(SRM390Medium,PaintingBoardsなど)・最短路問題(SRM479Medium,TheAirTripDivOneなど)・フロー(SRM428Hard,FeudaliasWarなど)・2-SAT(SRM464Medium,ColorfulDecoration)・閉路検出(SRM524Medium,LongestSequenceなど)といった具合に色々なアルゴリズムと組み合わせた問題があるのも楽しいところですね。
二分探索の注意点は単調性がちゃんと成り立ってるかを確認することですね。ぱっと見で単調性が成り立ってそうでも実はそうではなく、FailedSystemTestが大量発生したSRM483Hard,Sheepのような問題もあるので。
これは二分探索よりもさらに頻度が少ないですが、三分探索が必要な問題が出たときにきっちり解けると嬉しいですね。三分探索の概念自体は二分探索を知ってすぐに調べたのですが、「凸性があるということは微分すると単調性を持つということだから、別に三分探索自体は必須ではないのでは?」と思ってました。しかし次に挙げるSRM426Medium,CatchTheMiceと出会ってその考えは打ち砕かれることになります。
問題概要(CatchTheMice)
2次元平面状にn(2<=n<=50)匹のネズミがいて、初期位置をxp[i],yp[i]、速度ベクトルをxv[i],yv[i]で与えられている。ある時間に、辺が座標軸と平行な正方形の檻を平面に降ろしてネズミを全てその内部に捕まえたい。正方形の辺の長さの最小値はいくつか。
この問題は別の解法もあるにはあるのですが、三分探索を使えば圧倒的にシンプルに解くことができます。詳しい解説は省きますが、「xy平面上に直線がいくつかある時、f(x):あるx座標における直線のy座標の最大値(最小値)とおくと、f(x)は凸性を持つ」という性質を見つければこの問題に三分探索を適用することが出来ます。
同じくこの性質を使うことで、三分探索でシンプルに解ける問題としてSRM276Medium,TestingCarやSRM240Medium,WatchTowerなどがあります。また、関数f(x)自体は凸性を持ちかつ微分可能ではあるけど、xが離散的な値しか取らない(整数だけとか)ために三分探索を適用しないといけない場合もありますね。
これはアルゴリズムそのものというよりも、それが適応できる問題でどういう風に辺や点を取るかを考えるのが面白いって感じでしょうか。長くなっちゃうので問題詳細は省きますが、TCO10R5Medium,LongJourneyやそれと似たような問題であるSRM492Hard,TimeTravellingGogoあたりが好きなダイクストラの問題です。
上に挙げなかった以外で好きなSRMの問題です。
KSubstring(SRM404Medium)
長さn(2<=n<=3000)の数列が与えられる。ある長さmの2つの互いに重ならない部分列の和をそれぞれS1,S2とした時、最も小さいS1とS2の差と、それを取る時の最も大きいmを求めよ。
単純にやるとO(n^3)となってTLEするものをちょっとした工夫でO(n^2logn)にするという、自分の中では競技プログラミングの王道かなと思う問題のタイプです。特別なアルゴリズムの知識も必要なく実装量も少なめなので良い問題かなと。結構昔に解いたのですが、当時に比べ色々と知識が付いた今でも変わらず良問に思えたのでここで紹介しました。
TheAlmostLuckyNumbers(SRM453.5Hard)
全ての桁の数字が4または7の整数をLuckyNumber,少なくとも1つのLuckyNumberで割り切れる整数をAlmostLuckyNumberと呼ぶことにする。a以上b以下のLuckyNumberの数を求めよ。(1<=a<=b<=10^11)
包除原理という、ちょっとした数学(算数?)の知識を使うことでパズルみたいに解ける問題で楽しかったです。この問題のwriterはVasylさんという方なのですが、自分はVasyl問題が結構好きだったりします(問題名の頭にTheが付いてたら大体Vasylさんだと思います)。好きという割には結構Vasyl回でボロボロだったりするんですけどね…
何というか本当に自分の思うままに書いただけで、初心者向けでも上級者向けでもなくまさに誰得だよって感じの内容ですが、ここまで読んでくれた方はありがとうございます。ここに上げた問題はどれも良問だと思うので、是非解いてみたり、あるいは他の人のコードを読んでみたりするといいと思います。では皆さん、素敵なTopcoderライフを!